While trying to add gzip compression to a custom node.js reverse proxy server through connect's compress middleware, I ran into a really strange problem: my browser would fetch the first 5 resources without problems, then it would stall for 2 minutes before gettting the next 5 resources, stall for another 2 minutes for the next five, and so on.
If I waited long enough, all of the resources would be loaded correctly and the page would look fine.
This is what I saw in Firebug:
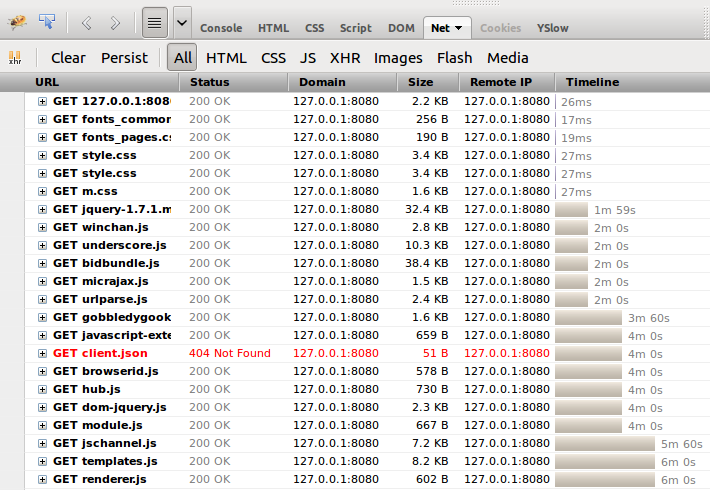
The Firebug documentation explains that the "blocking" state is the time that the browser spends waiting for a connection. Given that this was an HTTP connection (i.e. no SSL), I wasn't sure what was causing this but it looked like some kind of problem with the backend.
HTTP Keep-alive and the Content-Length header
Thanks to a brilliant co-worker who suggested that I check the content-length headers, it turned out that the problem had to do with persistent connections (HTTP keep-alive) being enabled and the middleware not adjusting the length of the body after compression.
In particular, what was happening is that the browser would request the first batch of resources (it appears to keep a maximum of 5 connections open at once) and receive gzipped resources tagged with the size of the original uncompressed resources.
In most cases, the compressed resources are smaller than the original ones and so the browser would sit on the connection, waiting for the remaining bytes until it timed out. Hence the fixed 2-minute delay for each batch of requests.
When using a persistent connection, browsers need a way to know when a given response is done and when to request the next one. It can be done through the content-length header, but in the case of compression, that would mean buffering the whole resource before sending it to the client (i.e. no streaming). An alternative is for the server to return the resource using the chunked transfer encoding. This is what compress does by default.
Solution for connect.compress() and http-proxy
My original goal was to enable a compression middleware inside a simple application that proxied HTTP content using the http-proxy node.js module.
The http-proxy documentation claims that it is possible and comes with an example program that didn't work for me. So I decided to replace connect-gzip in that example with the standard compress middleware that is now bundled with connect.
Unfortunately, because of the fact that the compress middleware needs to run before the rest of the response code, it would take a look at headers before they were written out and refuse to compress anything.
Once I worked around this, I discovered that compress would attempt to remove the content-length header from the proxied responses and switch to a chunked transfer encoding. However, because the header had not been written yet, this would have no effect and and the old content-length would stick around and break keep-alive.
The fix was simple: I simply had to make sure that compress has everything it needs from the headers before it starts compressing anything.
Incorrect Content-Length headers for compressed resources on Keep-Alive connections causes the connection to hang until the timeout expires.
This is exactly what was happening to me--thanks for the writeup.